Data Mesh is a new paradigm for managing complex data systems that seeks to overcome the limitations of traditional centralized approaches. It is a distributed, domain-oriented, and self-organizing model that enables organizations to scale their data systems while maintaining agility, flexibility, and autonomy. In this article, we will provide an overview of the Data Mesh concept, its principles, and its benefits. We will also discuss the challenges and risks associated with implementing a Data Mesh architecture and provide some practical recommendations for organizations interested in adopting this paradigm.
In today’s digital world, data is the lifeblood of modern organizations. Companies use data to gain insights into their customers’ behavior, optimize their operations, and develop new products and services. However, as data volumes and complexity continue to grow, managing data has become a major challenge for many organizations. Traditional centralized approaches to data management, such as data warehouses and data lakes, are struggling to keep up with the pace of change and the growing demands for data access and agility. This is where Data Mesh comes in.
What is Data Mesh?
Data Mesh is a new paradigm for managing complex data systems that was introduced by Zhamak Dehghani, a principal consultant at ThoughtWorks. Data Mesh is a distributed, domain-oriented, and self-organizing model that seeks to overcome the limitations of traditional centralized approaches to data management.
The Data Mesh model is based on four key principles:
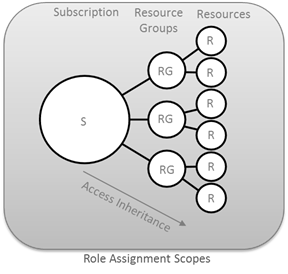
- Domain-oriented decentralized data ownership and architecture: In a Data Mesh system, data ownership and architecture are decentralized and domain-specific. Each domain is responsible for managing its own data and making it available to other domains as needed. This enables organizations to scale their data systems while maintaining agility, flexibility, and autonomy.
- Data as a product: In a Data Mesh system, data is treated as a product that is designed, built, and operated by dedicated data teams. These teams are responsible for ensuring the quality, reliability, and availability of the data products they create.
- Self-serve data infrastructure as a platform: In a Data Mesh system, data infrastructure is treated as a platform that enables self-serve data access and consumption. This platform provides a set of standardized APIs, tools, and services that enable data teams to create and manage their data products.
- Federated governance: In a Data Mesh system, governance is federated and domain-specific. Each domain is responsible for defining and enforcing its own governance policies and standards. This enables organizations to maintain consistency and compliance across their data systems while allowing for flexibility and autonomy at the domain level.
Benefits of Data Mesh
Data Mesh offers several benefits over traditional centralized approaches to data management. These include:
- Scalability: Data Mesh enables organizations to scale their data systems by decentralizing data ownership and architecture. This allows for more efficient data processing and faster data access.
- Agility: Data Mesh enables organizations to be more agile by empowering domain-specific teams to manage their own data. This reduces dependencies and enables faster decision-making.
- Flexibility: Data Mesh enables organizations to be more flexible by allowing for the use of different data technologies and tools within each domain. This enables teams to choose the best tools for their specific needs.
- Autonomy: Data Mesh enables organizations to maintain autonomy by allowing domain-specific teams to manage their own data and make their own decisions about data architecture, governance, and technology.
Challenges of Data Mesh
- Complexity:
Data Mesh architecture introduces additional complexity into the data system, which can be difficult to manage and understand. In a Data Mesh system, each domain is responsible for managing its own data, which can lead to duplication, inconsistency, and fragmentation of data across the organization. This can make it difficult to ensure data quality, maintain data lineage, and establish a common understanding of data across different domains.
- Integration:
Data Mesh architecture requires a high degree of integration between different domains to ensure data interoperability and consistency. However, integrating data across different domains can be challenging, as it requires establishing common data models, APIs, and protocols that are agreed upon by all domains. This can be time-consuming and resource-intensive, especially if there are multiple data sources and technologies involved.
- Governance:
Data Mesh architecture introduces a federated governance model, where each domain is responsible for defining and enforcing its own governance policies and standards. While this approach allows for more autonomy and flexibility at the domain level, it can also lead to inconsistencies and conflicts in data governance across the organization. Establishing a common set of governance policies and standards that are agreed upon by all domains can be challenging, especially if there are different regulatory requirements and data privacy concerns.
Risks of Data Mesh
- Data Security:
Data Mesh architecture requires a high degree of data sharing and collaboration between different domains, which can increase the risk of data breaches and unauthorized access. Ensuring data security and privacy across different domains can be challenging, especially if there are different security protocols and access controls in place. Organizations need to establish a robust data security framework that addresses the specific security requirements of each domain and ensures that data is protected at all times.
- Data Ownership:
Data Mesh architecture introduces a decentralized data ownership model, where each domain is responsible for managing its own data. While this approach enables more autonomy and flexibility at the domain level, it can also lead to disputes over data ownership and control. Establishing clear data ownership and control policies that are agreed upon by all domains can help mitigate this risk and ensure that data is used appropriately and ethically.
- Vendor Lock-in:
Data Mesh architecture requires a high degree of flexibility and interoperability between different technologies and platforms. However, using multiple vendors and technologies can increase the risk of vendor lock-in, where organizations become dependent on a specific vendor or technology for their data needs. Organizations need to establish a vendor management strategy that ensures they have the flexibility to switch vendors and technologies as needed without disrupting their data systems.
Conclusion
Data Mesh architecture offers many benefits, including improved scalability, agility, and flexibility of data systems. However, it also presents several challenges and risks that organizations need to consider before adopting this approach. Organizations need to establish a clear data governance framework, address data security and privacy concerns, establish clear data ownership and control policies, and develop a vendor management strategy that ensures they have the flexibility to switch vendors and technologies as needed. By addressing these challenges and risks, organizations can successfully implement a Data Mesh architecture that enables them to effectively manage their complex data systems.